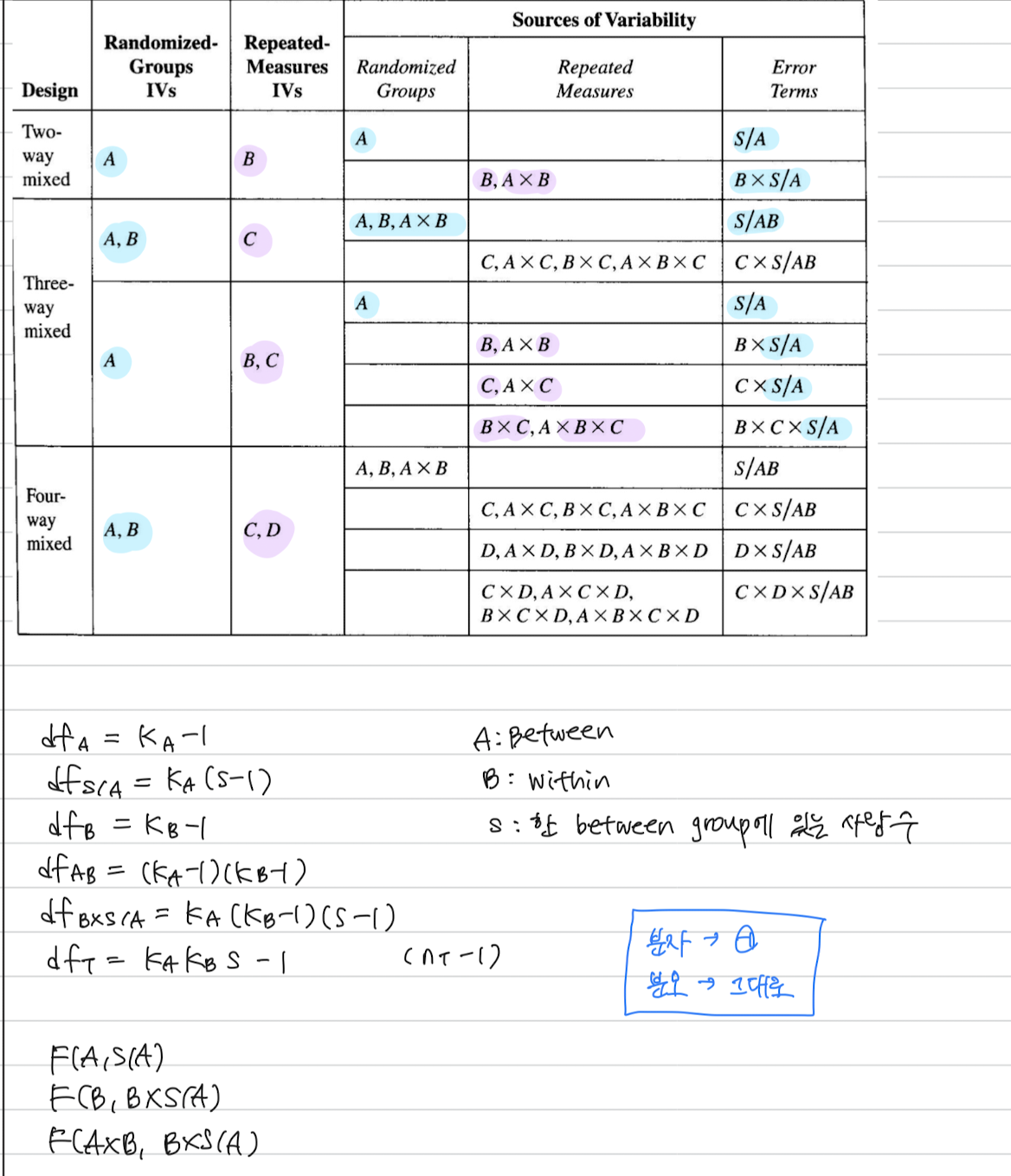
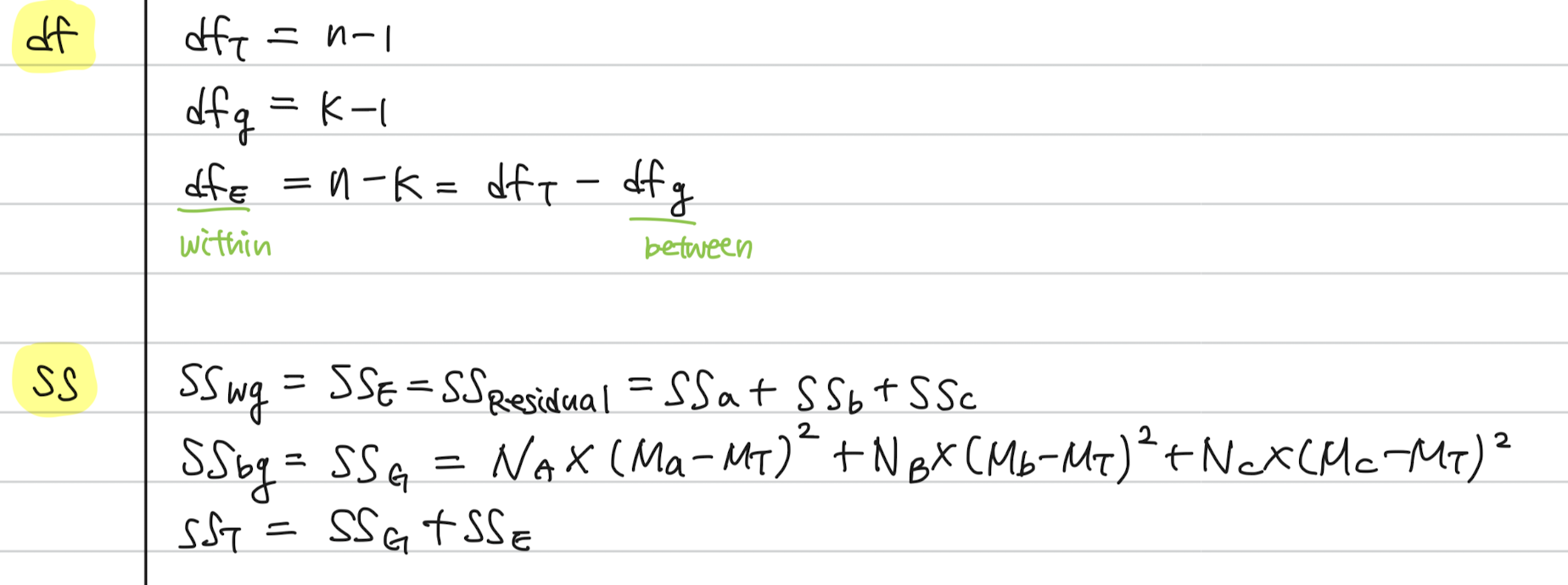p12Behavioral cloning은 왜 실패할까?training trajectory (data)의 분포를 pdata(ot)pdata(ot), 에이전트가 직접 운전하며 얻는 데이터를 pπθ(ot)pπθ(ot)라고 하자.여기서 문제는 policy가 학습된 분포 pdata(ot)pdata(ot)와 test되는 분포 pπθ(ot)pπθ(ot)가 다른 distribution shift가 생기긴다는 것이다.p13좋은 policy는 어떻게 측정할 수 있을까? pdata(ot)pdata(ot) 같은 행동을 할 가능성이 높은 것?그것보단 훈련 데이터와 다른 상황에서도 좋은 행동을 할 수 있는 policy→ cost를 정의하자.cost: human driver와 행동이 같으면 0, 다르면 1이제 목표..